Culture as Code · Speckit + Enforcement
I built the guardrails a team of 10 would need, for a team of 1, because shipping solo is when discipline compounds fastest.
Published
Culture as Code: Speckit and Enforcement
How I built the guardrails a team of ten would need, for a team of one, and why it turned out to be the highest-traction decision across four months of solo shipping.
Opening
The startup playbook is older than software. Move fast in the early days. Ship scrappy. Fix it later. AI hasn’t changed that advice; what AI has changed is that scrappy is no longer the price of fast.
You can now ship the codebase a senior systems architect would be proud of in roughly the time it used to take to ship the duct-taped MVP. The catch is that AI does not give you the discipline to do it. It only removes the excuse not to. You still have to know what great looks like, and you have to refuse to skip the parts you cannot see yet.
This is the case study for what that refusal looks like in practice. Four months of solo shipping, 38 numbered features, one constitution that grew the way every honest policy document grows: each principle added the day after I learned why it should have existed.
The problem
Solo shipping breaks in predictable ways, and AI-assisted coding multiplies all of them.
Past decisions go undocumented, so future-me cannot tell why the code is the way it is. Features drift: a spec starts as one thing and becomes another with no trace of the handoff. Every fix risks breaking something the original author already decided, and the original author is also me. AI assistants cheerfully rewrite a module in a style that contradicts three others it touches, and without rules of the road, the assistant is right that the rules do not exist.
Underneath all of this is the empty-review problem. Code review is where most engineering cultures enforce taste. Solo, there is no reviewer.
The team-of-ten answer is process: specs, ADRs, code standards, test gates, doc requirements, PR templates. The bet I made four months ago was that those artifacts are worth more to a solo dev than to a team, because a solo dev is the one who most needs to trust their own past self.
The workflow
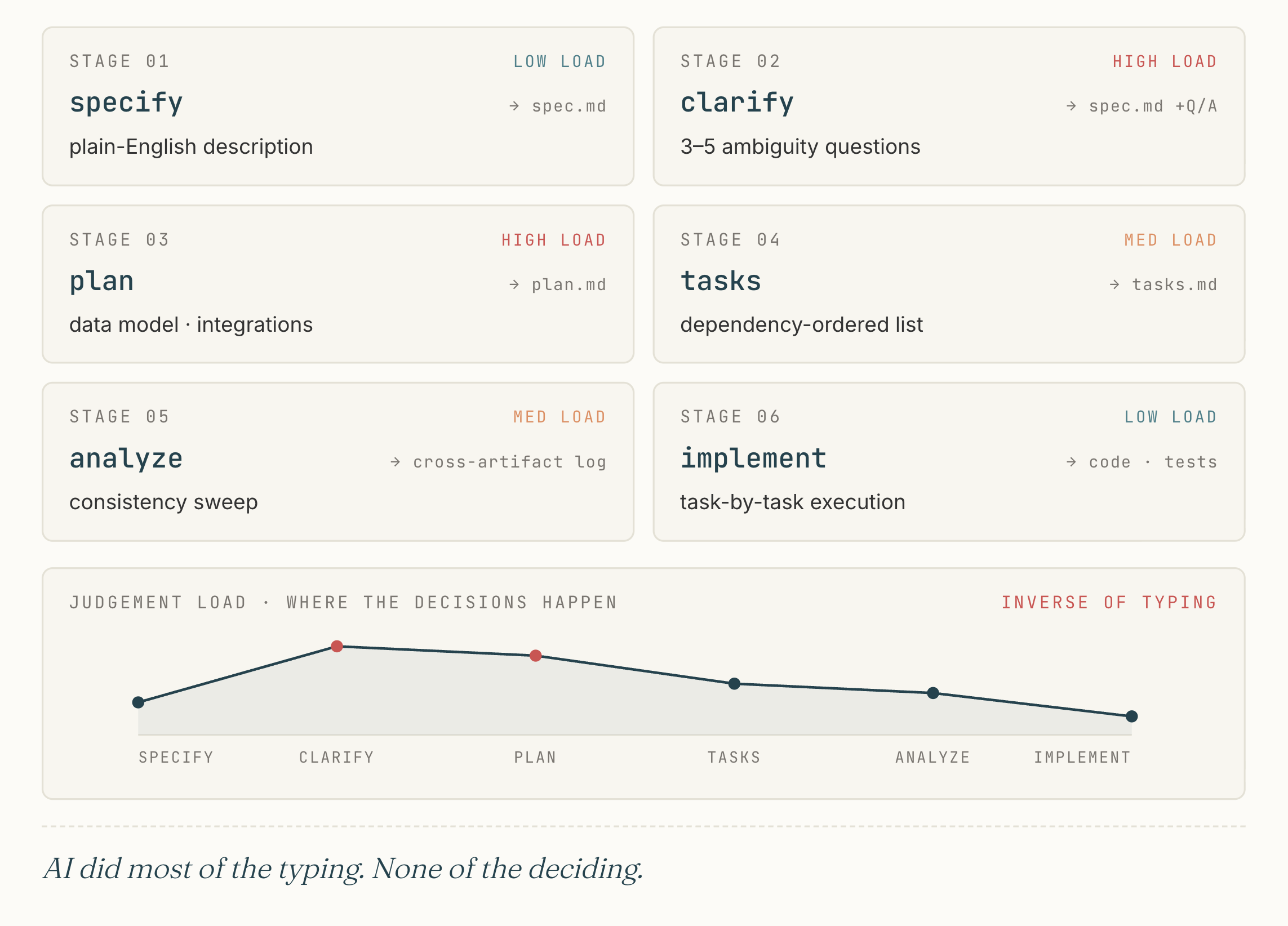
The workflow is built on Speckit, an open-source templating layer for AI-assisted feature specification. Speckit gives you the six stages and the templates; the discipline is in running every feature through every stage, every time.
Every feature in olllo, without exception, passes through these six stages before a line of implementation code is written.
The six stages:
specifygenerates aspec.mdfrom a plain-English feature descriptionclarifysurfaces 3–5 targeted questions about ambiguous requirements and encodes the answers back into the specplanproduces the technical design: data model, integration points, dependenciestasksproduces a dependency-ordered implementation list, each task with acceptance criteria and test-coverage requirementsanalyzeruns cross-artifact consistency across spec, plan, and tasks, catching contradictions before codeimplementgenerates code task-by-task with local test verification at each step
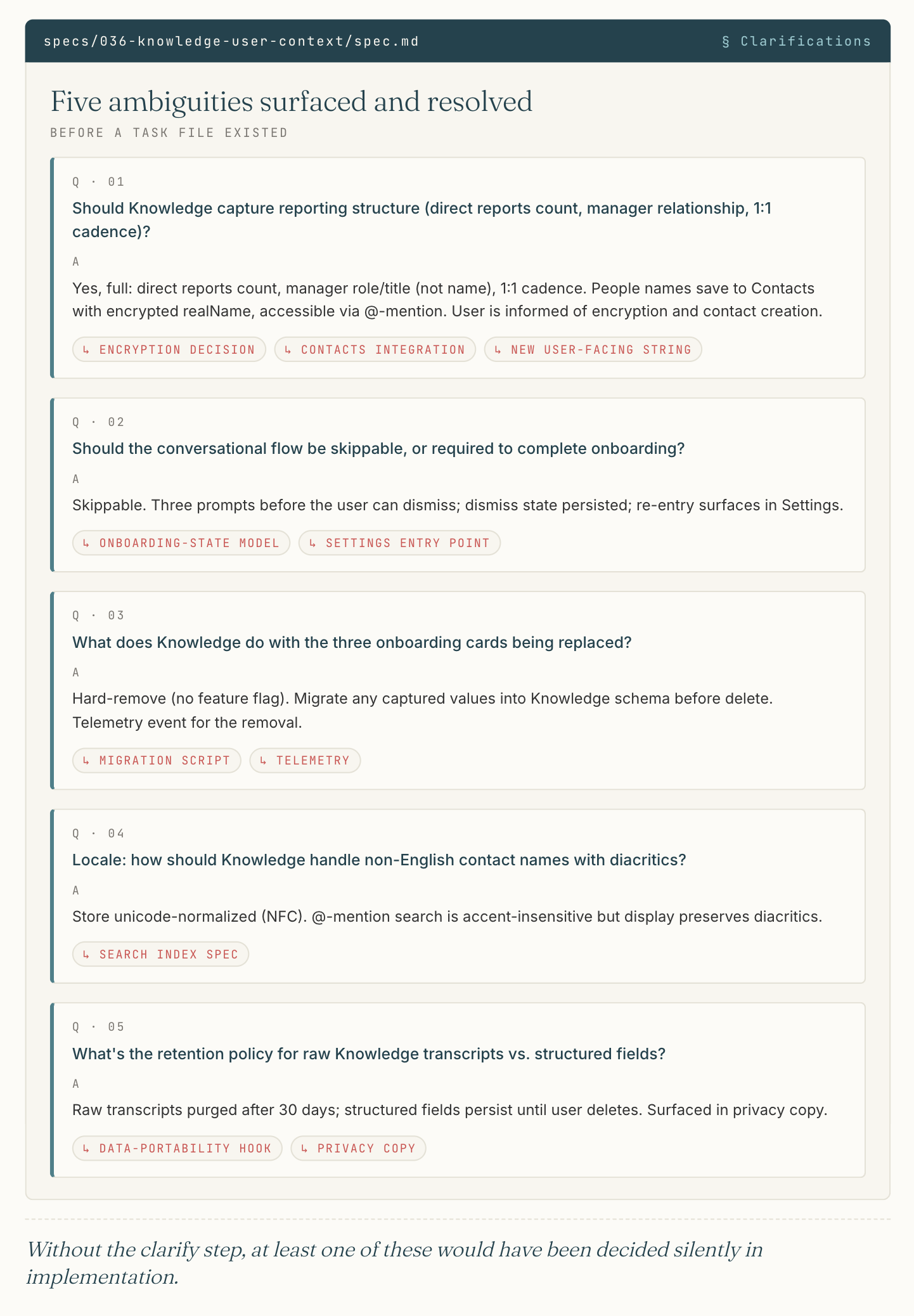
 A real example. Feature
A real example. Feature 036-knowledge-user-context replaced three existing onboarding cards (work context, preferences, notifications) with a single conversational AI flow. The spec.md has a literal “Clarifications” section with five Q/A pairs from the clarify stage. Each one is a decision that would have shipped as an unstated assumption without the process:
Q: Should Knowledge capture reporting structure (direct reports count, manager relationship, 1:1 cadence)?
A: Yes, full: direct reports count, manager role/title (not name), 1:1 cadence. People names save to Contacts with encrypted realName, accessible via @-mention. User is informed of encryption and contact creation.
That single clarification triggered an encryption decision, a Contacts integration, and a new user-facing string. Without the clarify step, at least one of those three would have been missed or decided silently in implementation.
 By the time implementation starts, the ambiguity budget is spent and implementation is execution rather than exploration.
By the time implementation starts, the ambiguity budget is spent and implementation is execution rather than exploration.
The implement stage is the loudest in any AI-assisted workflow. It’s where the assistant does most of the visible typing. But on every feature in olllo, my time was spent in the earlier stages: reading research, refining the spec, choosing the harder long-term path over the easier short-term one the research suggested. The clarify and plan stages exist to make those judgment calls visible. The implement stage exists to make sure the visible decisions make it into the code. AI did most of the typing. None of the deciding.
The spec directory for 036 ends up with nine artifacts:
 Every feature gets the same nine slots. Not all slots are always full; some are a single sentence. But the shape is the same, which is what makes two-month-old features readable.
Every feature gets the same nine slots. Not all slots are always full; some are a single sentence. But the shape is the same, which is what makes two-month-old features readable.
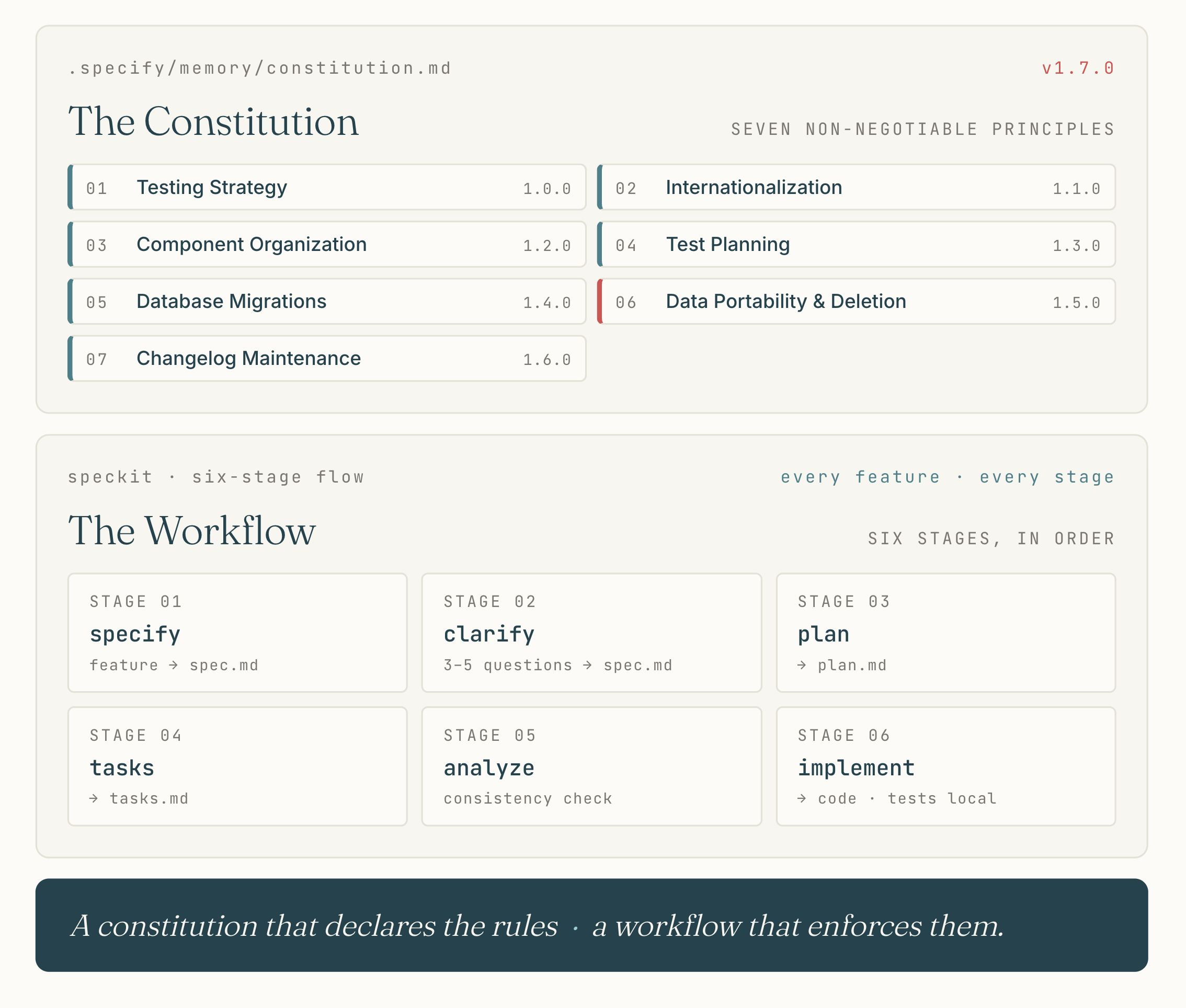
The constitution
The constitution is a single file, versioned like code: .specify/memory/constitution.md, currently at version 1.7.0, last amended 2026-03-23. It declares seven non-negotiable principles.
Each principle is declared, rule’d, and rationalised. Principle 5 exists because I lost data once. Principle 6 exists because GDPR Article 17 does. Principle 7 exists because I shipped changelog entries inconsistently until I made it mandatory.
 The file is amendment-tracked with semantic versioning. Every amendment is a scar.
The file is amendment-tracked with semantic versioning. Every amendment is a scar.

The gates
Principles are nothing without enforcement. The gates are where the discipline compounds.

Pre-merge, via CI
Every PR runs unit tests against the database package, against the app, and against shared packages, via .github/workflows/ci.yml. The build fails if any test fails. No “I ran it locally” exception.
Pre-PR, via the workflow itself
The speckit implement step refuses to create a PR if affected tests have not been run and passed locally. That rule lives in the constitution (Principle 4) and in the speckit templates, so it’s enforced both in the assistant’s behavior and in my own muscle memory.
Documentation, via required artifacts
A feature is not complete until spec.md, plan.md, and tasks.md exist. Implementation tasks reference constitution principles by number. When a new user-facing feature ships without a changelog entry, the analyze stage flags it.
Security, via four dedicated workflows
SAST, DAST, secret scanning, and dependency auditing run on every push. The existence of security-secrets.yml alone means a hardcoded API key won’t land even if I miss it in self-review.
AI behavior, via evals
ai-eval.yml runs model-output tests in CI. Changing a prompt without verifying downstream output would be trivial to do by accident without this gate; with it, prompt changes are gated on measurable behavior.
Living context, via CLAUDE.md
The assistant reads CLAUDE.md on every session. When conventions evolve, the file is updated in the same PR as the convention change. The assistant’s suggestions stay aligned with current standards instead of drifting toward training-data defaults.
What the gates didn’t catch
Most case studies on engineering process tell the story of the time the gate caught a bug. This one tells a different story: the time the gate didn’t, and what came of it.
On 2026-01-13, I added Principle 6 to the constitution: every new user-data model must update the export and deletion services. The principle was added during the GDPR/CCPA work, when I had just built the services and discovered that “every model” was a longer list than I’d assumed.
Eighteen days later, on 2026-01-31, I pushed ea14b27 directly to master: fix(database): add quarterly review models to user data services. A feature I’d shipped between those two dates had added new user-data models without updating the services. The principle existed. The enforcement was still me. I missed it during the feature, caught it in self-review later, and patched it with a direct push.
That is a near-miss, and it is the kind of near-miss that the rest of the constitution exists to make rarer. Read the version history again with this in mind:
- 1.6.0 (2026-02-05) added Changelog Maintenance after I shipped features without changelog entries
- 1.4.0 and 1.5.0 (2026-01-13) added Database Migrations and Data Portability the day I felt the absence of both
- 1.3.0 (2025-12-13) added Test Planning after I shipped tests as follow-up work and watched coverage drift
- 1.7.0 (2026-03-23) added Local Test Verification during feature 038, after a CI failure that would have taken fifteen seconds to catch locally
Every amendment is a postmortem encoded as a rule. Read top to bottom, the version history is a curriculum: every lesson I’d want to teach the next person on day one, in the order I learned it the hard way.

The outcome
38 numbered feature branches shipped between December 2025 and March 2026. Branches 001 through 040, with two gaps where features were consolidated. Every one followed the same six-stage workflow. Every one produced the same nine artifacts in its spec directory. Every one was gated on tests and documentation before merge.
The measurable consistency: a feature from two months ago is readable in minutes, not hours. The spec tells me what we decided, the clarifications tell me why, the tasks tell me what was built, the constitution tells me what rules applied. There is no archaeology. There is only reading.
The trade was never about speed; it was about debt. Every startup I have watched at scale has hit the same wall: things start breaking at year two because the early observability was thin, the early tests were inadequate, the early decisions were unwritten. Retrofitting those things at scale costs more than building them at month one would have. Speckit and the constitution were the bet that I could pay that cost up front, every feature, and ship a codebase without a debt cliff to climb later.
What I’d port to a team
Universal, ship day one:
- The constitution as code, versioned with amendments
- The speckit
clarifystage as a required step for any feature spec - Test tasks in the same task file as implementation tasks, not in a follow-up
- CI enforcement of every non-negotiable rule, not convention
Solo-only, probably cut on a team:
- The full nine-artifact spec directory. A team version would consolidate into three:
spec.md,plan-plus-tasks.md,decisions.md. - The
implementstage’s requirement that the assistant runs tests locally. On a team, CI is the gate. - Principle 7’s “when in doubt, ask” clarify step for changelog entries. A team would codify this in the PR template and skip the clarify roundtrip.
The biggest constraint, and the part I would reframe before bringing this approach to a team, is that Speckit was built for one author. The artifacts it produces (spec.md, plan.md, tasks.md, decisions.md) are excellent for me-to-future-me communication. They are hard to share for in-progress feedback. There is no good way for a teammate to comment on a plan that is still being written, no way for a designer to weigh in on a clarification before it is resolved, no way to fork a plan into alternatives and pick between them. A team version of this approach needs a collaborative layer: shared workspace for in-flight specs, async comment threads on clarifications, plan branching and review. That is the next thing I would build if I took this to a team.
Secondary gap: a lightweight ADR workflow outside of features. Cross-cutting decisions (“switch from Postgres full-text search to pgvector”) currently live in whatever feature spec happens to touch them, which is the wrong home. The specs/adr/ directory exists but is underused.

Why the discipline compounds
Process discipline reads as overhead until the moment it isn’t, and the moment it isn’t is usually six weeks after a decision you made is now haunting you. Solo devs do not have a senior engineer down the hall to ask. They have their past self, who will either have left notes or not.