AI Product Craft
AI features only feel good when the model, the latency, the reliability, and the UX are designed together, not layered.
Published
AI Product Craft: When the User Is in the Moment
How models got matched to tasks, agents got scoped to outcomes, and structure beat prompting at every step. A walk through the four-tier model config, a multi-agent spec that replaced a broken one, and an eval harness that runs every night.
Opening
The user is in the moment. They are typing a sentence about a meeting that just ended, rating the week they just had, or asking the assistant to help them prep for a 1:1 in fifteen minutes. Every AI call had to fit inside that moment.
Three things picked the model that handled it: speed, correctness for the task, and cost. The first two are why this case study leads with latency budgets and tier-to-task fit. The third was a real factor in every decision, never the lead one. Cost is the reason the system does not run Opus on everything; it is not the reason any specific model got picked.
Pick the wrong tier and the user feels the lag. Pick the wrong agent boundary and the assistant talks past them. Pick the wrong scope and the assistant talks about itself instead of about them. This is the case study for how I picked, three decisions deep: the tier, the agent, and the line between what the model gets to decide and what the code does.
The constraint that picked the model
Model tier configuration lives in packages/ai/lib/config/model-tiers.ts. Four tiers, each with a primary model, a fallback, a timeout, a retry count, a temperature, a max-token cap, and a budget cap.
micro Gemini 2.0 Flash Lite Haiku fallback 3s t=0.1 512 tok $0.005
fast Claude Haiku 3.5 Gemini Flash Lite 5s t=0.2 1024 tok $0.01
balanced Claude Sonnet 4.5 Gemini 2.0 Flash 15s t=0.5 4096 tok $0.10
advanced Claude Sonnet 4.5 Claude Opus 4.5 30s t=0.7 8192 tok $0.50
Read it left to right and the design intent is plain. Each tier is organized around a latency budget (3, 5, 15, 30 seconds across the four) because that is what the user feels first. Temperature climbs as the task gets more generative. Token caps grow with the task’s natural length. Cost grows with model size and with the chosen primary; the per-request budget caps exist so a runaway loop cannot bankrupt the system, not as the lever that decides which model runs.
PII detection runs on the micro tier because the user is mid-sentence and the model cannot afford to think for two seconds. Refinement chat sits at balanced because the assistant is in dialogue, the user is reading the words as they stream, and a half-second to first chunk is good enough. Reflection conversation runs at advanced because it is the deepest, most generative use of the system, and by the time it starts the user has already committed to the moment.
Every tier has a fallback model from a different provider. Every request routes through Vercel AI Gateway, which is enabled: true everywhere with no opt-out. The gateway gives unified logging, request-level cost tracking, and rate limiting. That is the observability layer that makes everything else in this case study possible. If you cannot see what your AI is doing, you cannot improve it.

Where single-agent got stuck
For the first version of weekly reflection, I built what every AI product builds: a single agent with a long, well-prompted system message, a list of themes to cover, and a hard cap on total questions. The prompt told the agent how to move through the themes, what each one should cover, when to summarize, when to wrap up. It did not work.
The diagnosis is in specs/012-reflection-multi-agent/spec.md. The production data captured there:
- Goals theme received 14 questions (target: 2)
- Well-being received 4 questions (target: 2)
- Engagement received 3 questions (target: 2)
- The agent sometimes declared completion while themes remained under-covered
The root cause, written in my own words in that same spec, is the entire lesson of this section:
A single LLM cannot reliably track multi-theme state and enforce hard limits through prompting alone. The agent “forgets” constraints as the conversation progresses.
Prompts are wishes. The longer the conversation, the more the wish decays. A reflection that should have run twelve questions across five themes in three minutes was running twenty-five questions about goals, abandoning users halfway through.
 The mistake I see most often in AI product work is to respond to this kind of failure with better prompts. Longer prompts. Cleverer prompts. The mistake is mine too; the early iterations of the reflection prompt are still in git history, each one longer than the last, trying to encode the constraints more emphatically. None of them moved the needle past a certain point, because the model was never the right place to encode hard constraints.
The mistake I see most often in AI product work is to respond to this kind of failure with better prompts. Longer prompts. Cleverer prompts. The mistake is mine too; the early iterations of the reflection prompt are still in git history, each one longer than the last, trying to encode the constraints more emphatically. None of them moved the needle past a certain point, because the model was never the right place to encode hard constraints.
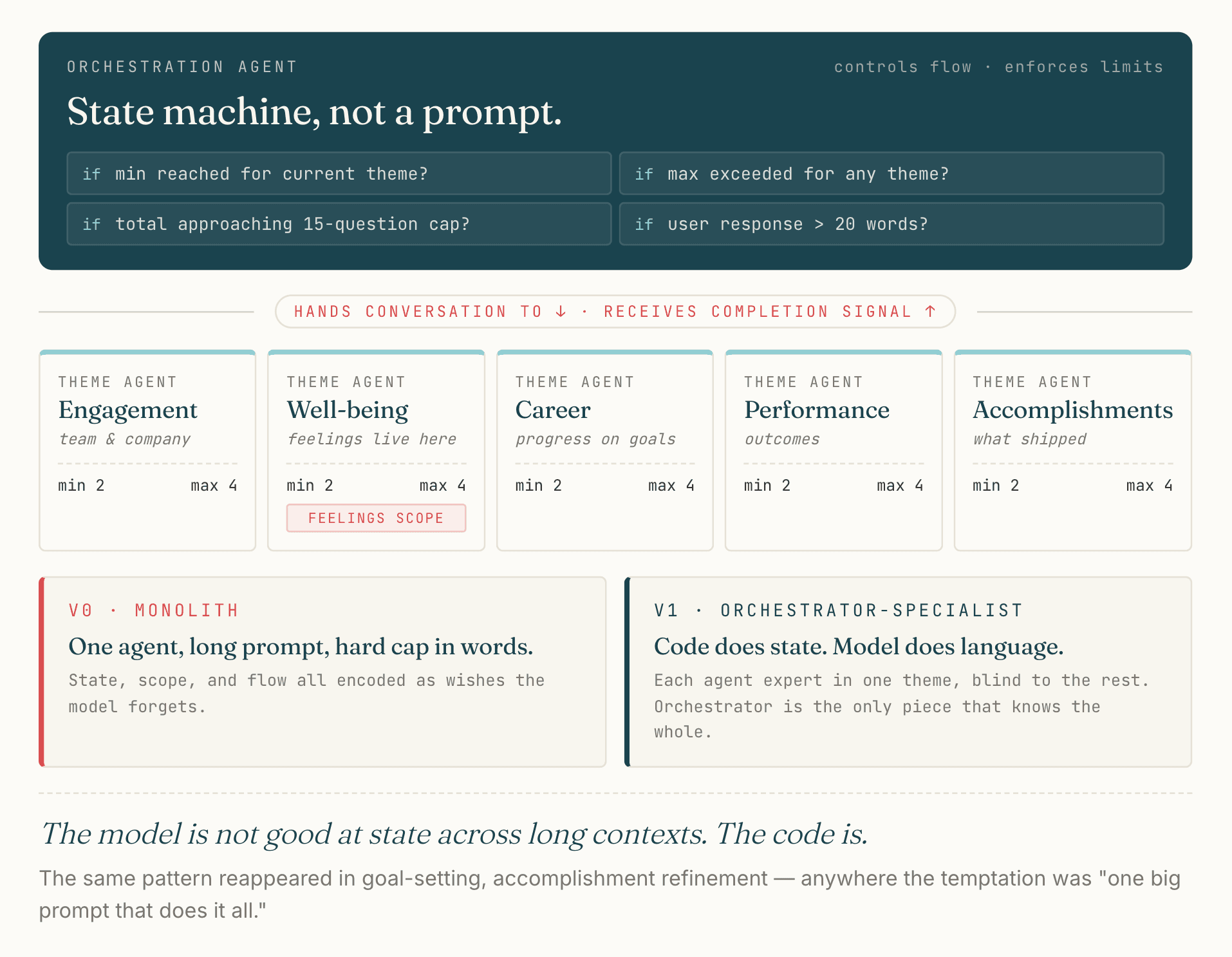
The orchestrator-specialist pattern
The fix was structural, not prompted. The new architecture, shipped as feature 012, replaces the monolithic agent with three layers:
- An orchestration agent that controls flow and enforces limits with hard state checks in code, not in prompts
- Theme-specific agents (Engagement, Well-being, Career, Performance, Accomplishments) that each focus on a single domain for 2 to 4 questions
- A response-length heuristic that decides whether to continue or transition: continue if the user’s response is under 20 words, transition after 2 questions otherwise
The orchestrator’s job is the part the model could not do reliably: state tracking. Has Engagement reached its minimum? Has any theme exceeded its maximum? Is total question count approaching the 15-question cap? Those are programmatic checks now, not prompt requests. The orchestrator hands the conversation to the next theme agent when its checks say so.
Each theme agent is what an engineering manager would call an expert: scoped to a focused outcome, expert in reaching it, blind to everything else. Engagement does not know about Career. Career does not know about Well-being. The orchestrator is the only piece that knows the whole. That separation is what kept the conversation moving.
 The same pattern reappeared in goal-setting, in accomplishment refinement, anywhere the original temptation was “one big prompt that does it all.”
The same pattern reappeared in goal-setting, in accomplishment refinement, anywhere the original temptation was “one big prompt that does it all.”
What the model wanted to talk about
The most useful thing I learned about AI product craft is that the model has biases that prompting alone cannot suppress.
In the single-agent reflection, even with explicit prompts telling the agent to spend most of its questions on the user’s actual work and impact, the conversation kept drifting toward feelings. How do you feel about your week? How did that meeting make you feel? How do you feel about that? It was not what users wanted, it was not what the prompt asked for, and the system kept doing it anyway.
Telling the model to stop did not work. I tried. Several times.
The fix was not a sharper prompt. The fix was scope. The Well-being agent talks about feelings; that is its job. The other four agents are not allowed to. Performance asks about outcomes. Career asks about progress toward stated goals. Engagement asks about team and company connection. Accomplishments asks about what shipped. None of them have permission to ask “how do you feel about that,” because that question lives in a different agent’s scope and the orchestrator hands the conversation off when it is time.
The lesson that generalizes: when the model wants to do something the product does not want, give the unwanted behavior its own scope and gate it. Telling the model “do not do X” is a wish. Building the system so X is structurally unavailable outside the agent that handles X is law.

The reliability layer
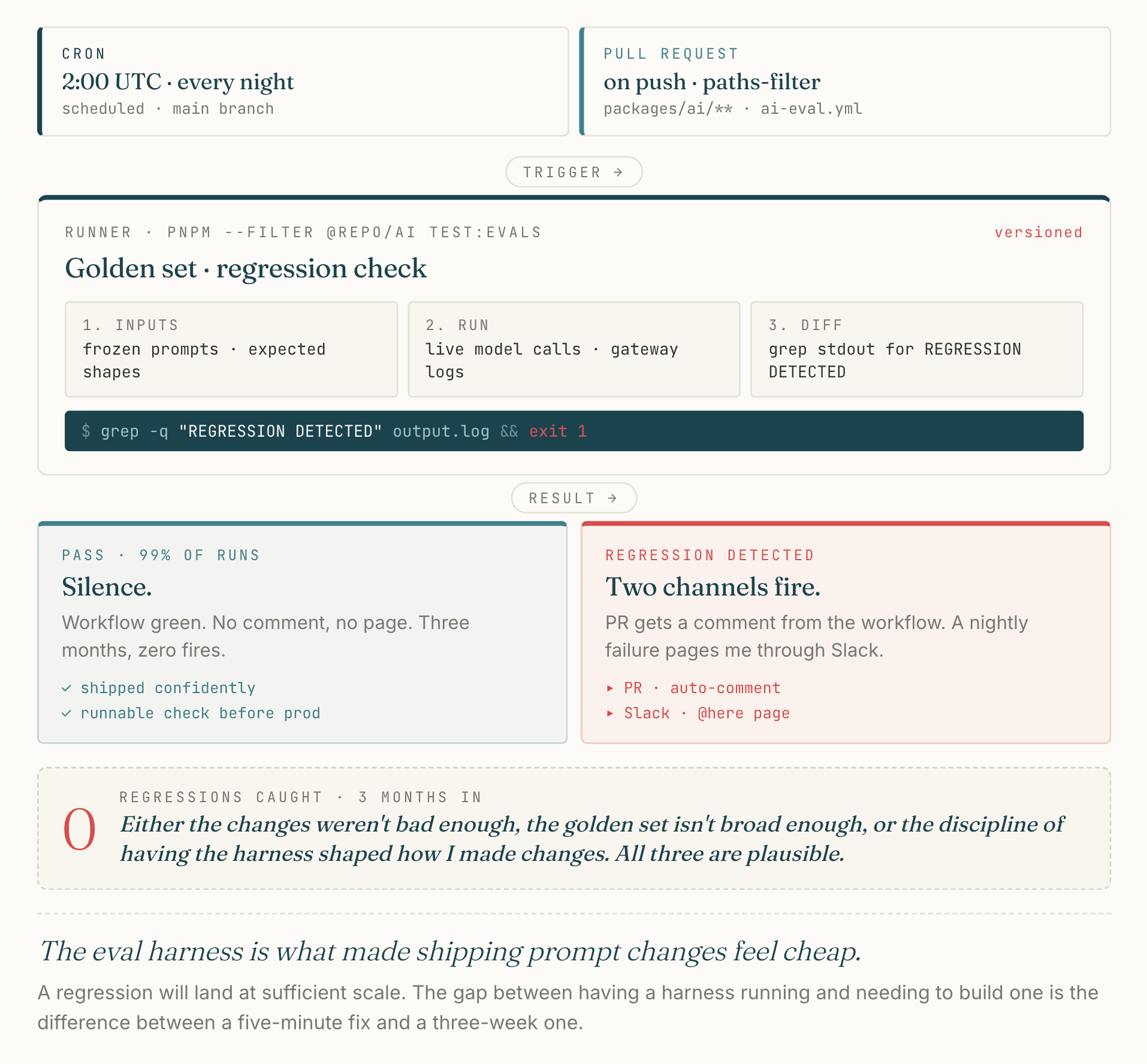
The eval harness lives in .github/workflows/ai-eval.yml. It runs nightly at 2 AM UTC and on every PR that touches packages/ai/**, the AI services in the database package, or the eval workflow itself. The harness uses a versioned golden set, runs evaluations through pnpm --filter @repo/ai test:evals, and grep’s the output for the literal string REGRESSION DETECTED. Any regression fails the workflow and posts a comment on the PR. A nightly failure pages me through Slack.
A specific regression the harness has caught, in four months of operation: none. That is worth being honest about.
I cannot tell you whether that is because my prompt changes were never bad enough to trigger one, because the golden set is not broad enough to catch the subtle drift that would have shown up at scale, or because the discipline of having the harness shaped how I thought about prompt changes in the first place. All three are plausible.
What the harness did was let me ship prompt changes more confidently, because there was a runnable check between me and production. That confidence was worth building even when nothing was ever flagged. At sufficient scale, a regression will land. When it does, the gap between having an eval system already running and needing to build one is the difference between a five-minute fix and a three-week one.
The other reliability pieces are smaller but worth listing. Vercel AI Gateway in front of every request, for unified logging, observability, and a single rate-limit chokepoint. Upstash Redis for request-layer rate limiting beyond what the gateway handles. Retry policies declared per tier, two to three attempts depending on tier. Streaming timeouts that distinguish between total request time, time to first chunk, and chunk-to-chunk stalls. None of these are novel; all of them are the boring infrastructure that turns a demo into a product.
What I’d take into another product
The tier abstraction. Picking a model per task is the wrong unit of decision; picking a tier and assigning tasks to it is the right one. The tier captures the latency budget, the temperature philosophy, the retry policy, and the safety caps in a single object that downstream code references by name. New AI feature, new tier assignment, zero fresh decisions about timeouts or fallbacks.
The orchestrator-specialist split for any conversation that needs to move through structured phases. Reflection, goal-setting, performance prep, anything that has phases. The model is not good at state across long contexts. The code is. Let each one do what it is good at.
The eval harness as a non-negotiable. Building AI features without an eval harness is shipping a product whose quality you cannot measure. Even a small golden set with regression detection on PR is enough to start; the discipline of running it grows the set over time.
The boring observability. AI Gateway, request logs, cost tracking, rate limiting. None of this looks like AI product craft on a portfolio. All of it is what makes the AI product behave like a product instead of a demo.
The meta-point
AI product work has three layers that get conflated. There is the model layer, where the choice is which model, what temperature, what budget. There is the orchestration layer, where the choice is what the model decides and what the code decides. There is the scope layer, where the choice is what each agent is allowed to talk about.
The mistake I made early, and that I see often elsewhere, is to handle all three through prompting. Better prompts, longer prompts, cleverer prompts. None of it works past a certain point because the model was never the right place to encode hard constraints, define state machines, or scope domains.
The right division of labor: the model decides language, the code decides flow, the scope decides domain. Once those three layers are separate, the model’s biases stop being problems and start being characteristics you design around.
