Architecture & Technology
A solo-built Turborepo with 40+ shipped features across web, native mobile, and PWA runs on a handful of load-bearing decisions.
Published
Solo Architecture: Nine Apps, Twenty-One Packages
A walk through the olllo monorepo: what was built, what held up, and what I would reconsider with four months of hindsight.
Opening
Architecture for one is a different problem from architecture for many. The team-of-ten answer is to design for handoffs, parallelism, and reviewer load. The team-of-one answer has to design for someone else: future-you, who will inherit every decision in three months and not remember why.
The olllo monorepo is the version of that I shipped. Nine apps, twenty-one packages, thirty-eight numbered features over four months. Most of it I would build the same way again. Some of it I would not. This case study is the honest version of both.
The shape
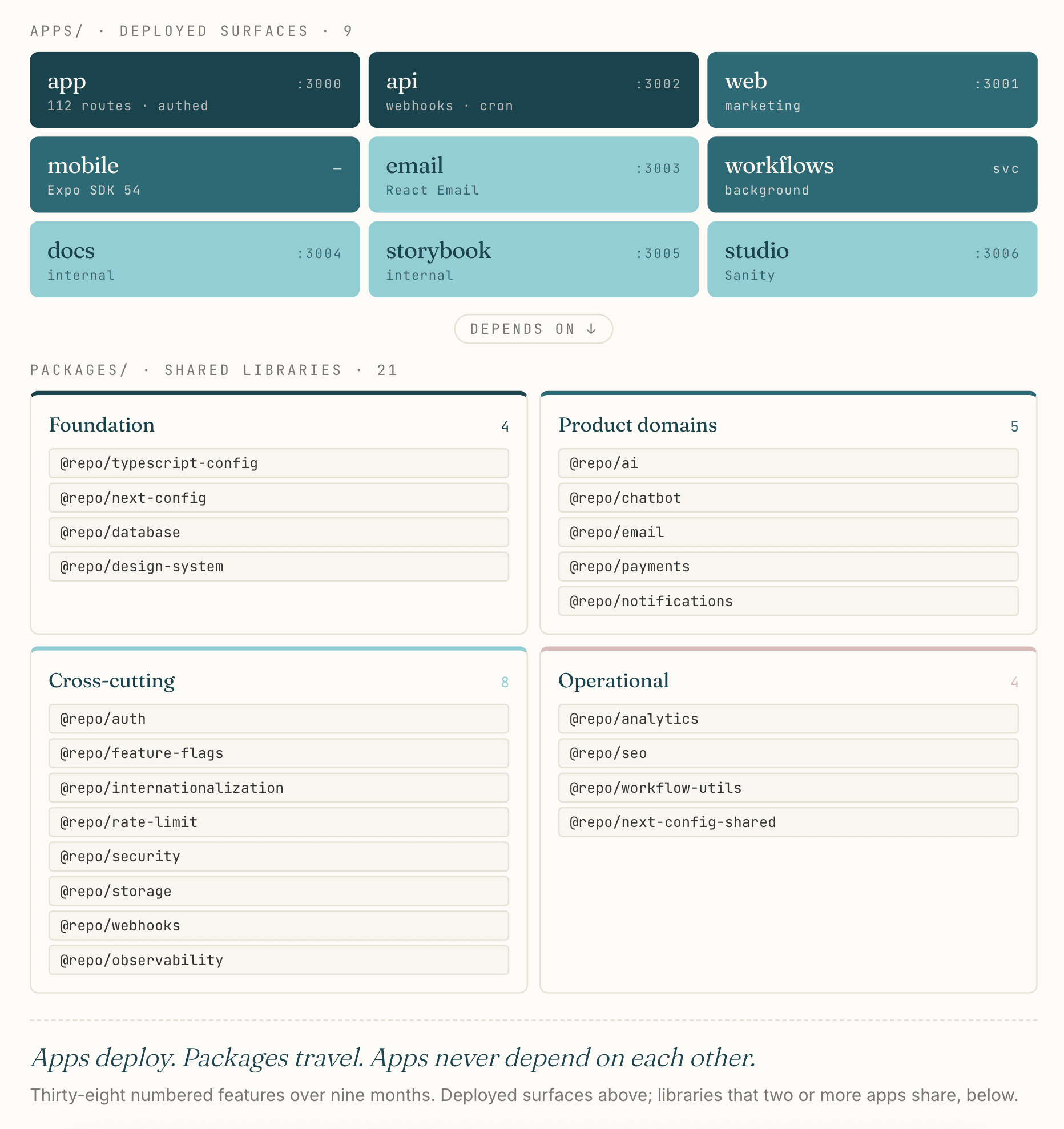
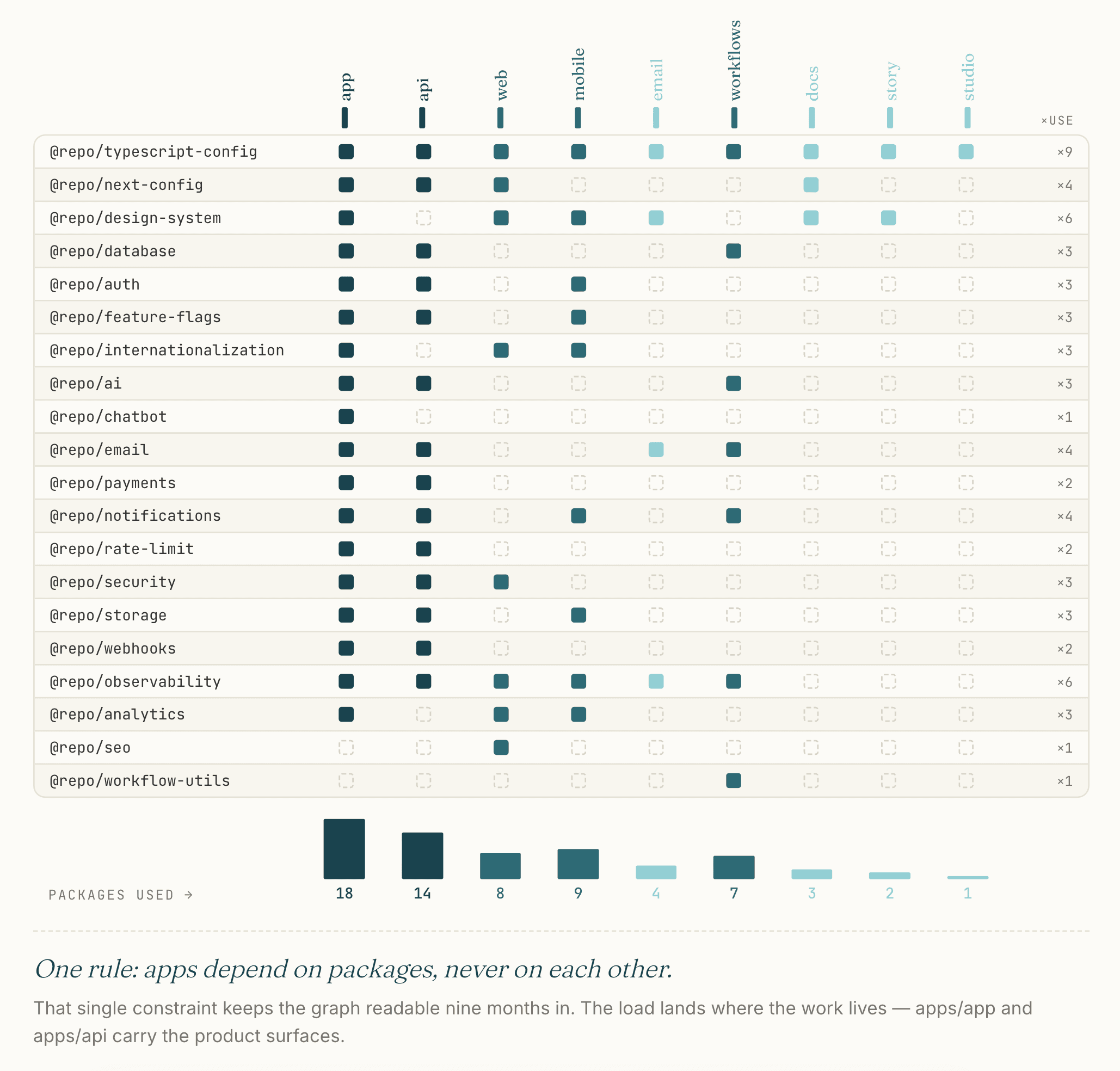
The repo is a Turborepo workspace on top of pnpm. The split between apps and packages is the spine: apps are deployed surfaces, packages are libraries that two or more apps share.
The apps:
app: the authenticated product where users live, Next.js 16 on the App Router, 112 API routesapi: the webhook + cron + admin surface, deployed separately fromapp(more on this below)web: the marketing sitemobile: the iOS/Android client (Expo SDK 54)email: the React Email preview appdocs,storybook,studio: internal toolingworkflows: background jobs deployed as a separate service
The packages, grouped by what they do:
- Foundation:
typescript-config,next-config,database(Prisma),design-system(shadcn/ui-based, with the caveats in Cross-Platform Consistency) - Product domains:
ai,chatbot,email,payments,notifications - Cross-cutting:
auth(Clerk),feature-flags,internationalization,rate-limit,security,storage,webhooks(Svix-based outbound),observability(Sentry + Logtail) - Operational:
analytics,seo,workflow-utils
This is more surfaces than a typical solo product. The shape is intentional: each app is a separate deployment with separate concerns, each package is a boundary I knew I would want to swap or scale independently.
Decisions that held up
Four architectural choices I would defend in a hostile interview.
Splitting apps/api from apps/app
apps/api is its own Next.js deployment on its own port (3002 in dev). It serves only inbound webhooks (Clerk auth, Stripe payments, Resend email), cron endpoints (keep-alive, drip emails), and a thin admin API. The user-facing routes live in apps/app, which has 112 API routes for product features.
The reasons are practical. Webhooks need signature verification and no Clerk session; product routes need exactly the opposite. BotID protection lives on api, not on app. A flaky Stripe handler should not be able to take down the user-facing app. Webhook load is bursty and external; product load is smooth and authenticated. None of those concerns alone are decisive; the combination is what made the split worth maintaining.
The cost is one extra Next.js app to deploy and a slightly more complex local-dev story (the Stripe CLI forwards to port 3002, the app runs on port 3000). The benefit is that I never had to think about “should this middleware run on the webhook” or “what if this cron starves the product.”
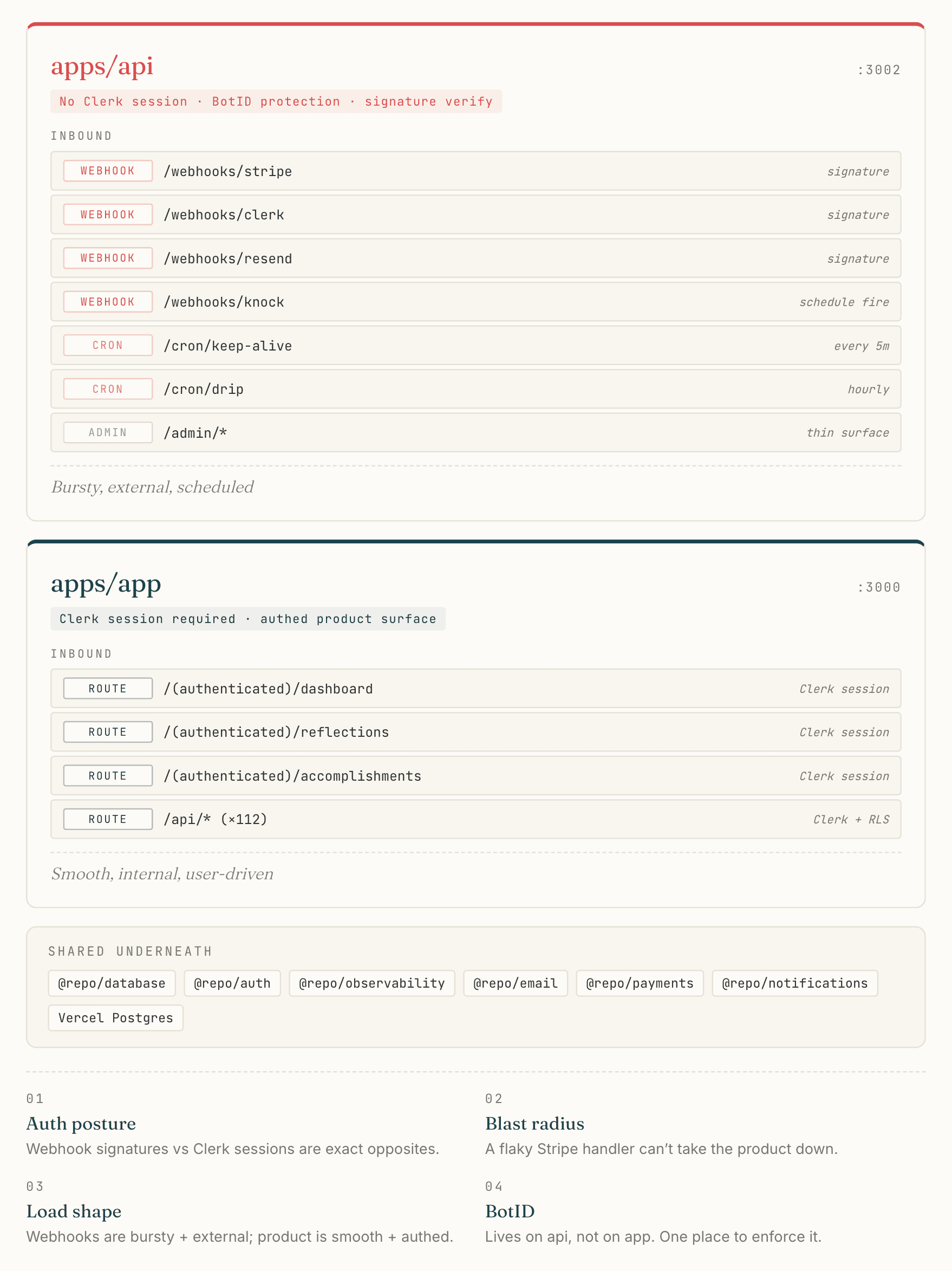 The four reasons the split is worth maintaining, side by side. Auth posture and load shape diverge cleanly across the boundary; blast radius and BotID enforcement only work because the boundary exists.
The four reasons the split is worth maintaining, side by side. Auth posture and load shape diverge cleanly across the boundary; blast radius and BotID enforcement only work because the boundary exists.
Vercel AI Gateway as a universal chokepoint
Every AI request in the system routes through Vercel AI Gateway. The config in packages/ai/lib/config/model-tiers.ts declares enabled: true and there is no opt-out. AI Product Craft covers the AI design in detail; architecturally, the gateway is the single most consequential decision in the AI surface.
One observability surface. One rate-limit boundary. One cost-tracking layer. One place to swap providers underneath. When Anthropic releases a faster model, the swap is a config change. When I want to know what the system spent on AI yesterday, the answer is one screen. When I add a new AI feature, none of the observability work is fresh.

Single Postgres + single Prisma schema
The data layer is one Vercel Postgres instance with one Prisma schema covering everything: user data, marketing consent, subscriptions, accomplishments, reflections, goals, contacts, notification events. No separate marketing DB, no separate auth DB, no separate analytics DB.
The temptation to split was always there. Each domain feels like it deserves its own schema. The reason I did not split is that the data needs to join. Marketing consent correlates to billing status. Onboarding completion correlates to reflection cadence. Notification eligibility correlates to feature flag state. Splitting the database would have produced sync work for no real isolation gain: the same JOIN logic, just spread across services and probably implemented as a custom event bus that nobody asked for.
A team would eventually outgrow this default. A solo product never reached the size where the limits showed.
The four-layer component hierarchy
Components live in one of four places, codified in the constitution:
packages/design-system/components/: UI primitives, no business logic (shadcn/ui base + form wrappers)apps/app/components/{domain}/: used across two or more featuresapps/app/app/(authenticated)/_components/: layout shell (sidebar, header, nav)apps/app/app/(authenticated)/{feature}/_components/: feature-route components
The decision tree fits on one page of the constitution. New component, single question: where does this live? The answer is determined, not negotiated. There is a promotion path when a component graduates from feature-route to app-shared to design system.
The reason this held up: solo, the temptation is to treat every component as worthy of promotion to design system because you have seen it twice. The hierarchy makes you wait until the third use, which is when the abstraction is actually safe. Most components stay in _components folders, which is exactly where they should be.
 Four layers, one decision tree. New component? Single question: where does this live? The answer is determined, not negotiated.
Four layers, one decision tree. New component? Single question: where does this live? The answer is determined, not negotiated.
Decisions I’d reconsider
Expo for mobile
The mobile app is Expo SDK 54. I would not use Expo if I were starting today.
The reasoning is direct experience. Since shutting down olllo, I have spent time in pure native iOS development, and the experience of controlling the build, debugging across the simulator and a physical device, and shipping changes is materially better without the translation layer. Expo’s promise is “write JavaScript, ship to two platforms.” The promise is real. The cost is also real: when something breaks, the surface area of “is this a JS bug, an Expo SDK bug, a Metro bundler bug, an iOS-Expo-config issue, or a real native bug” is wide. With native, the surface is narrower, the tools are sharper, and the debugger does not lie to you about what is on the device.
For a solo product genuinely targeting both iOS and Android from day one, Expo is still defensible. For a solo product where iOS is the primary surface (which is what olllo’s mobile ended up being once usage data showed where the users actually were), I would write Swift.
The half-built analytics abstraction
packages/analytics is named for swappability. Call sites import analytics from @repo/analytics rather than from posthog-js, which is exactly what you would want if you ever needed to swap providers. The boundary is at the import path.
The methods underneath are not abstracted. analytics.capture(), analytics.identify(), analytics.flush() are PostHog method names. The package re-exports posthog-js directly with a renamed identifier. The server-side variant instantiates new PostHog(...) and the noop development shim mimics the PostHog interface.
Now that I am moving off PostHog (the UI is harder to use than I expected, the Slack integration is shallow, the views I want are easier to build myself), the incompleteness is visible. Two paths forward:
- Build the homegrown analytics layer to match PostHog’s method API. The package swap stays at one file.
- Update all the call sites to a new API. The package shape changes too.
Either works. The lesson is that a half-abstraction is worse than no abstraction in one specific way: it makes you think the swap is cheaper than it is. A package boundary named for swappability looks like an interface; it isn’t, until the methods underneath are wrapped too.
If I were doing this again, I would either go all the way (a generic capture/identify interface, PostHog wrapped inside it) or not at all (call sites import posthog-js directly, with a one-time migration cost when the swap eventually came). The middle path is the expensive one.
Bought vs built
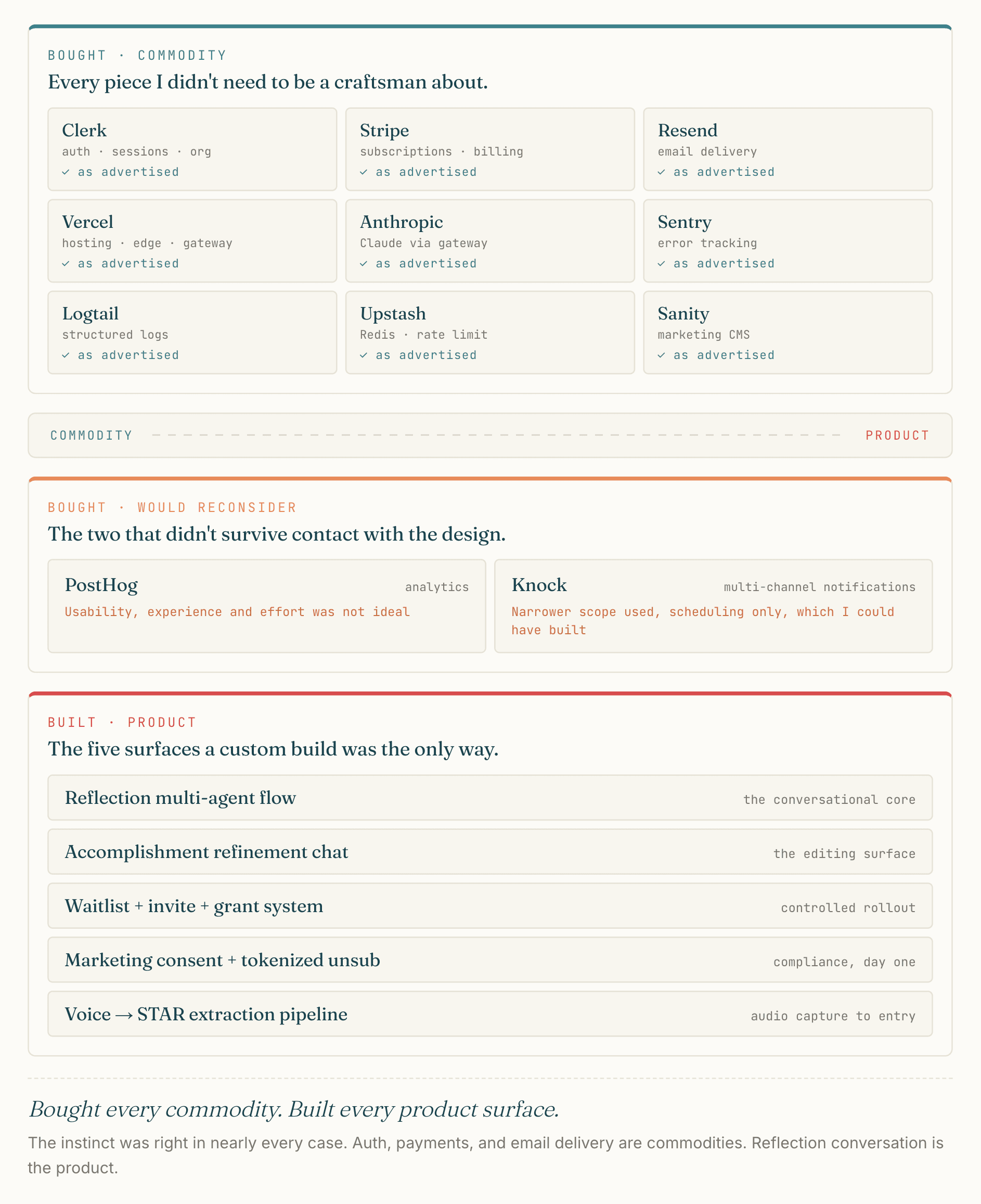
Things I bought:
- Clerk (auth, sessions, social login, org management, webhooks)
- Stripe (subscriptions, billing, customer portal)
- Resend (transactional + marketing email)
- Knock (multi-channel notification routing, user preferences)
- Vercel (hosting, edge runtime, AI Gateway)
- Anthropic via the gateway (Claude models)
- Sentry (error tracking)
- Logtail (structured logs)
- Upstash Redis (rate limiting)
- Sanity (marketing copy CMS)
Things I built:
- The reflection multi-agent flow (see AI Product Craft)
- The accomplishment refinement chat
- The waitlist + invite + free-forever-grant system (see Growth Engineering)
- The marketing email consent + tokenized unsubscribe (see Growth Engineering)
- The voice capture pipeline (audio captured, transcribed, then extracted into a STAR-format entry)
The split is roughly: bought every commodity, built every product surface. The instinct was right in nearly every case. Auth, payments, and email delivery are all commodities. Reflection conversation is the product, and a custom build was the only way it could have worked.
Two vendor decisions look different in hindsight than I thought they would when I picked them.
PostHog for a homegrown analytics layer. The product was harder to use and integrate than I expected, especially around chart customization and Slack alerts. I have started building lightweight in-app analytics tailored to the metrics olllo actually needed, and it has been surprisingly cheap. There is complexity I might be missing that PostHog handles for free: funnel tools, retention cohort math, session replay. Whether the homegrown version stays simple as I add use cases is the open question.
Knock turned out to be narrower than I bought it for. I picked Knock for multi-channel notification routing across email, in-app, and push, with user preferences and a send-history API. In practice I used it only for schedule management. Keeping email styling consistent across olllo meant rendering templates inside my own @repo/email package and sending them through Resend, so the real flow is: Knock fires a scheduled webhook, apps/api listens, the email package renders, Resend delivers. The promise of Knock-as-multi-channel-sender did not survive the practical need for consistent email design. With hindsight, I would consider replacing the Knock dependency with a cron and my own scheduling, since the value I extracted was the schedule, not the multi-channel send.
The rest of the bought stack paid off cleanly. Clerk, Stripe, Resend, Vercel + AI Gateway, Sentry, Logtail, Upstash, and Sanity all behaved as advertised and saved meaningful build time on day one.
Why solo
The honest answer to “why solo” is not “I prefer working alone.”
I started olllo with a co-builder, and after about a month they became unavailable. I had two options at that point: pause and find another co-builder, or absorb the second seat and keep going. The architecture decisions documented above are mostly downstream of choosing to keep going.
A co-built version of olllo would probably look different. Some of the structural discipline I imposed on myself (the constitution, the spec gates, the four-layer hierarchy) exists because the team-of-one cannot rely on review to enforce taste, so it has to be codified. With a second engineer, more of the discipline could have been informal. With a third or fourth, more of the package boundaries would have been driven by ownership rather than coupling.
The architecture is what it is partly because of who built it. That is worth saying out loud rather than pretending the structure was always the plan.
What I’d take into another product
The apps + packages split, with a Turborepo backbone and a pnpm workspace. Universal default for any product more complex than a single Next.js app.
The webhook/cron deployment isolation. Anything that runs on someone else’s schedule (Stripe, Clerk, Resend, cron) belongs in its own deployment with its own auth posture. This will not feel necessary on day one. It will feel obvious by month three.
The four-layer component hierarchy, codified in a constitution. Cheap to enforce, expensive to retrofit, scales to a team without modification.
The AI Gateway pattern. Whatever provider you pick, route everything through one chokepoint, get observability for free, treat model swaps as config rather than refactors.
The single-database default. Split when you have a reason. Do not split because the domains feel different.
What I would not bring forward: Expo, the half-abstracted analytics layer, and the way I integrated Knock without checking that the multi-channel send promise would survive my own design constraints.
The meta-point
The point of architecture in a solo + AI build is not to look like a senior engineer. It is to make decisions that compound, draw boundaries that future-you will recognize, and skip the abstractions that are flattering on day one and expensive on day ninety.
Most of what I built was the right shape. The pieces I would swap are the ones where I drew a line and then did not finish enforcing it. A package called @repo/analytics that exposes PostHog’s method surface is dishonest in a small but consequential way. Future-you will believe the package name and discover the cost at the exact moment the swap was supposed to be cheap.
The architectural taste I want to carry forward is unsentimental about that. Either the boundary is the interface, or the boundary is just a folder. Both are fine. The thing to avoid is the boundary that pretends to be an interface and is not.